Företag genererar mer och mer data och all den datan har ett stort värde, åtminstone om du har koll på vad du har och vad du kan använda den till. Du behöver sedan säkra så att datan inte används på ett annat sätt än vad just du vill.
Hur har det här hanterats tidigare?
I många fall så har det använts olika verktyg för att hantera olika typer av data från olika plattformar och tjänster. Ett verktyg för att hantera ERP-data, ett verktyg för Azure och ett för Amazon.
Detta gör att man får en administrativ mardröm och gör dataklassificering över plattformarna och tjänster väldigt svårhanterlig. Data växer, lagras och delas ständigt i nya riktningar.
En del av utmaningarna för datakonsumenter
Traditionellt så har identifiering av företagets datakällor varit en organisk process baserad på kunskap inom företaget. För företag som vill få ut det fulla värdet av sina informationstillgångar innebär det här många utmaningar.
- Tack vare att det inte finns någon central plats att registrera datakällor kan användarna vara omedvetna om vissa datakällor inom företaget.
- Om användarna inte vet vart källan finns, kan dom inte ansluta med klientprogram till sin data. Man måste då veta connection strings eller sökvägen.
- Om man har frågor om en informationsresurs måste man hitta det team eller expert som ansvarar för data.
En del av utmaningarna för dataproducenter
Dataproducenter delar de utmaningar som nämns ovan men har även en del egna utmaningar.
- Att lägga till förklarande metadata är ofta bortkastad tid. Klientprogram ignorerar oftast detta.
- Det kan vara svårt att dokumentera datakällor och hålla den synkroniserad.
- Det är utmanande att begränsa tillgången till datakällan men samtidigt se till att konsumenterna vet hur de begär tillgång.
Hur kan detta hanteras nu?
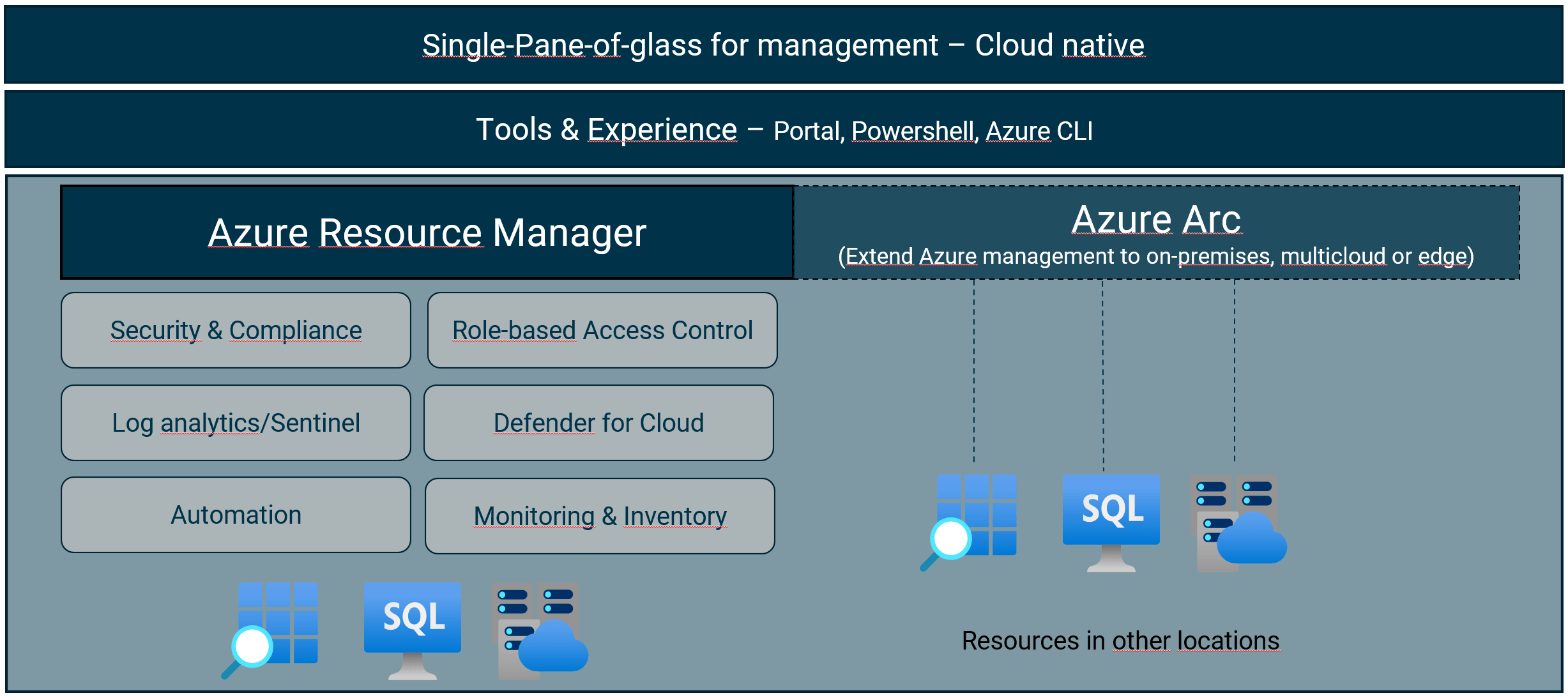
En tjänst som Microsoft satsar mycket på och som nyligen vart allmänt tillgängligt är Azure Purview.
Denna tjänst är skapad för att kunna få en enhetlig datastyrning. Tjänsten kan hantera och styra din data lokalt, i flertal molnplattformar och SaaS (programvara som en tjänst). Purview skapar en holistisk och uppdaterad karta över ditt datalandskap med automatiserad dataidentifiering, dataklassificering av känsliga data och end-to-end data lineage.
I skrivande stund finns det 30 källor som Purview kan ansluta till. Bland dessa finns Azure Data Lake Storage Gen2, Amazon S3, SQL Server, Google BigQuery mm.
Denna lista utökas hela tiden.
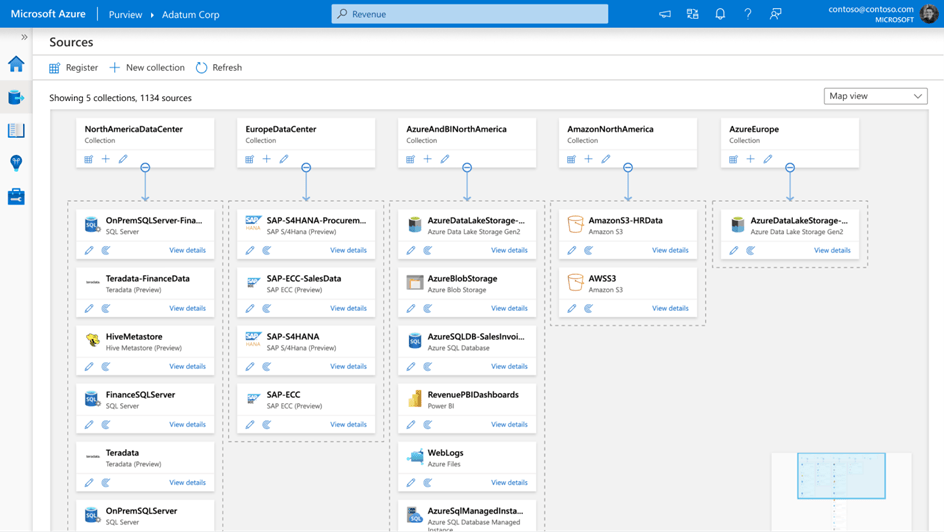
När en datakälla registreras i Purview så läggs en kopia av dess metadata till, tillsammans med en referens till datakällans plats.
Sedan kan du bygga på denna metadata genom att ange beskrivningar, taggar eller annan metadata
Detta kan sedan användas av företagsanvändarna för att identifiera och förstå datakällor och deras användningsområden. Företagsanvändare behöver data för business intelligence, programutveckling, datavetenskap eller andra uppgifter där rätt data krävs.
På samma gång kan användarna bidra till katalogen genom att tagga, lägga till beskrivningar och kommentera datakällor som redan har registrerats.
Microsoft 365 Sensitivity Labels går att applicera på all denna data. Sätt sedan policys på vad som får göras med datan som är klassat på ett visst sett, exempelvis att en viss typ av data inte får lämna företaget via mail.
Så har du koll på ditt företags datalandskap?